
Hello Everyone !! I hope you enjoyed my previous blog. Let’s deep dive into how to design Azure SQL Database disaster recovery. High availability and business continuity will help you to continue with your business in the event of a disaster. This blog will focus on how to set up Azure SQL Database disaster recovery , as a result of this design your database and application will be available all the time.
Disaster Recovery solution:
You can set up the disaster recovery solutions for your SQL Server database in Azure by database mirroring, availability groups, and restore and backup with storage blobs. Now will learn step by step solution for disaster recovery for SQL Database.
SQL Server database
Below you can see the SQL Server and Azure Database which is live production database. Live production database can be unavailable due to disaster or cloud hosting issue which will bring your Azure database down.
Using the Geo replication set up the Azure SQL database and make sure that your application is up and running in other words set up the secondary database.
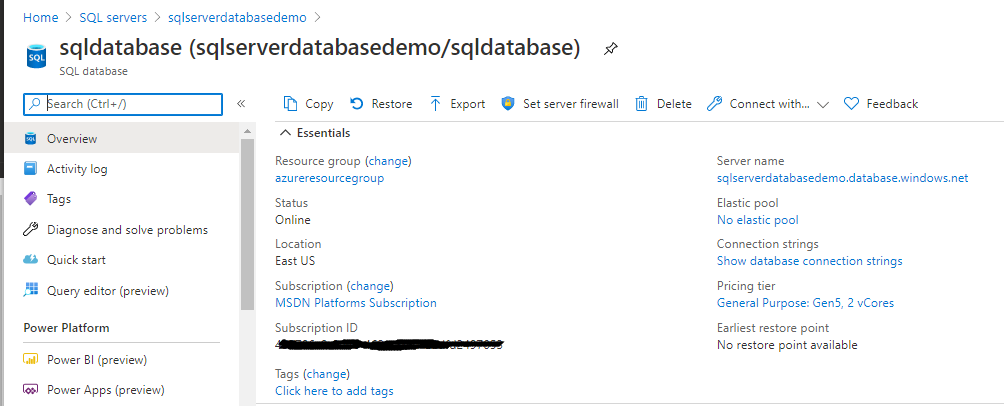
Set up the Geo Replication database
Click on the geo-replication button as a result of that you will get the options to choose the different regions for the secondary database.
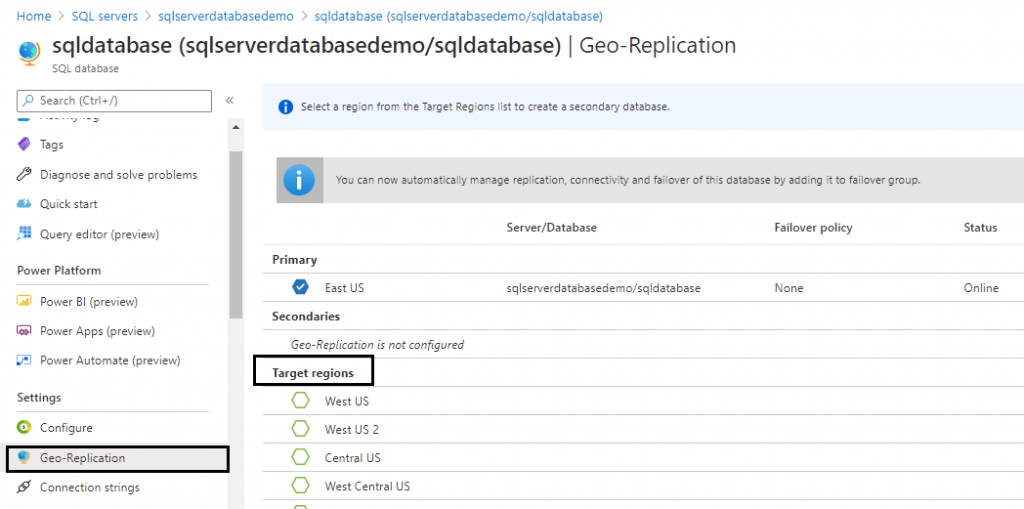
Select the anyone of the target regions where the secondary database needs to be set up by configuring the below details like target server, Elastic pool and pricing tier.
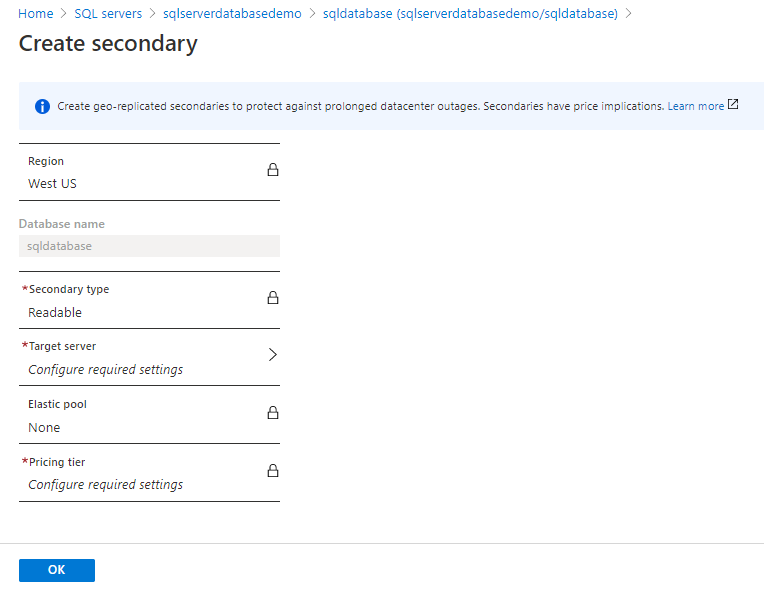
After creating the secondary server you can view your both the server as per the below screen shot.
You can see that Primary server is in the East US and secondary server is in West US.
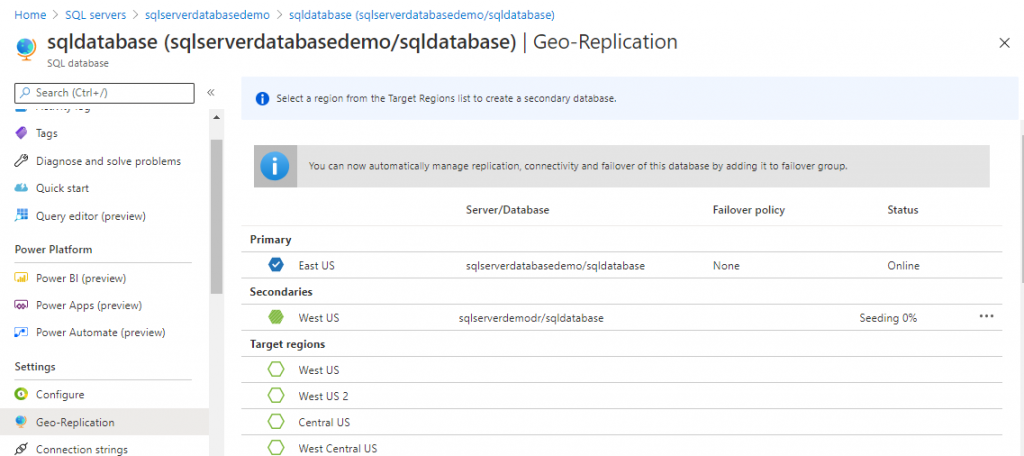
Now let me tell you how the disaster recovery server works. The primary server is where you have to perform all your operations. The secondary server replicates the operations performed in the Primary Server.
As a demo purpose you can create one table and populate few data in it. This operation you have to do it in the primary server.
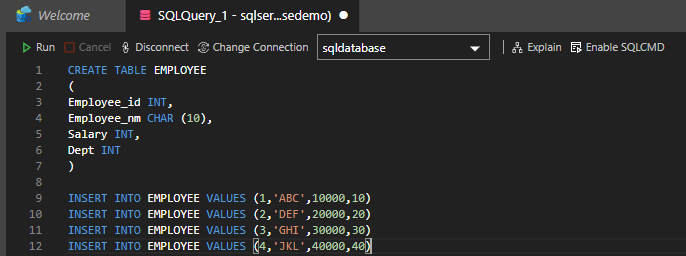
Check the secondary database for the seeding and asynchronous replication with primary database.
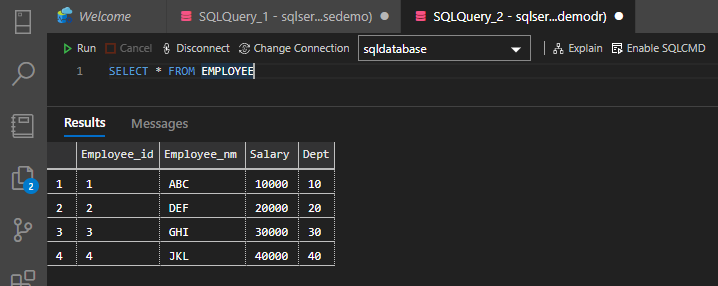
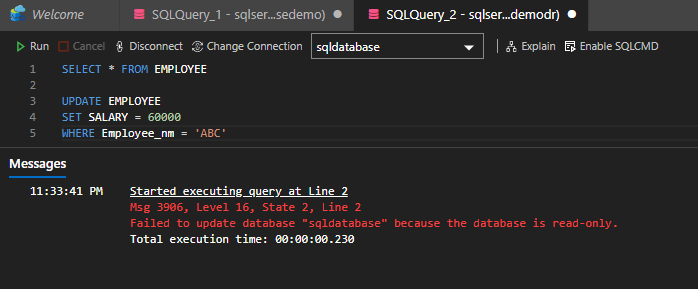
Secondary database is Read-Only mode and you cannot do any operations like DDL and DML.
Active geo-replication terminology
Asynchronous Replication: Secondary database server populates with the data copied from the primary database. The process of copying the data from primary to secondary is known as seeding. Transactions are committed on the primary database and before they are replicated to the secondary database is called Asynchronous replication.
Readable secondary databases: The secondary database is accessible only in Read-only mode with the same or different security principles. The secondary database works as snapshot isolation mode which ensures that updates in the primary database seeds to the secondary database without any delay.